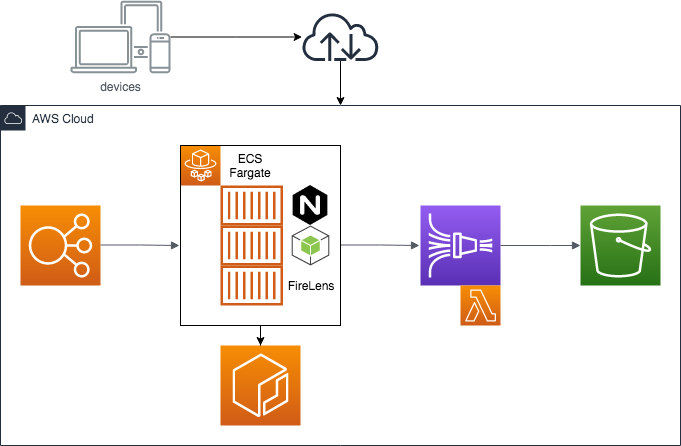
前回までのまとめ
前回、dockerのログが16kで分割されてしまう原因がdockerのログドライバの制限のためだったというところまで記載しました。
今回は分割されたログをどのようにして結合したかを記載したいと思います。
そういえば、分割されるとなぜ困るのかを記載してなかったかもしれません。なぜ困るかというと、ログはJSONで、分割されると妥当なJSONではなくなってしまうからです…
結合する方法
試してみた方法を2つ紹介します。
lambdaで結合する
最初はKinesis Data Firehoseで設定したLambdaで結合しようと試みました。
前回に少し紹介した、ログに含まれる分割されたかどうかを示す情報を元に、結合する場合は改行コードを追加せず、JSONの終端の場合は改行を追加するようにしました。
Lambdaはこんな感じになりました。
1 | exports.handler = async (event, context) => { |
改行を付与する(=結合するかどうか)条件は関数にまとめてみました。このように行うことで、ログは適切に結合されました。
Lambdaで結語することの問題点
無事ログを結合することができたのですが、Kinesisでバッファリングしたデータを出力するタイミングが必ずしもログを結合したあととは限りません。
ですので、なにが起こるのかというと、S3に保存されるファイルは、約1/2の確率で、分割されたログで終わってしまっているのです。
これでは解決になっていません。Kinesisに渡される前に分割されたデータを結合しないといけないということがわかりました。
代替案の検討
Kinesisに渡される前となると、FireLensで出力されたときには結合されていないといけません。つまり、FireLensで結合しないといけないということになります。
FireLensは、以下のクラスメソッドさんの記事を参考に設定しました。
https://dev.classmethod.jp/articles/ecs-firelens/
ここでは、FireLensのコンテナイメージとして、AWSが提供するaws-for-fluent-bit:latestを利用しています。
しかし、fluent-bitにはログを結合するプラグインはこの記載時点では存在していませんでした。fluentdにはログ結合のためのプラグインが存在していました。
よって、fluentdを使ってログの結合を行おうと思います。
fluentdで結合
fluentdで受け取ったログを結合するにはconcatプラグインを利用します。また、Kinesis Data Firehoseと接続するためにkinesis接続用プラグインも利用します。
concatプラグインはこちら
https://github.com/fluent-plugins-nursery/fluent-plugin-concat/
Kinesisのプラグインはこちら
https://github.com/awslabs/aws-fluent-plugin-kinesis
fluentdのイメージ
ではまずfluentdでログを結合するためにfluentdのベースイメージを探そうと思います。fluent-bitはAWS推奨のイメージがありましたが、fluentdにはないようです。ですので、公式のイメージをベースイメージとしました。
Dockerfileは以下になります。
1 | FROM fluent/fluentd:v1.9.1-1.0 |
1箇所、不思議な点があります。
1 | COPY fluent.conf /fluentd/etc/fluent-custom.conf |
こちらですが、fluent.confではなくfluent-custom.confとしています。なぜかというと、fluent.confはECS FireLensで自動的に上書きされてしまうため、ファイル名を変更してfluentdのホスト内に置いておきます。
fluent-custom.confの内容は以下になります。
1 | <filter firelens**> |
<label @TIMEOUT>については、また次回紹介します。
プラグインの設定のみ行なっています。sourceディレクティブを入れると、
1 | unexpected error error_class=Errno::EADDRINUSE error="Address in use - bind(2) for 127.0.0.1:24224" |
と表示されてエラーになってしまいます。この辺りはECSが自動的に設定してくれるので、必要最小限の設定で動作します。
こちらでビルドし、ECRにpushします。
タスク定義ファイルの修正
ECSのタスク定義ファイルを変更します。以前はfluent-bitを利用していたので、fluentdに変更する必要があります。
イメージの変更
まずはイメージを変更します。
1 | { |
ここで一旦デプロイしてみましたが、エラーが発生しました。
1 | Unable to generate firelens config file: unable to generate firelens config: unable to apply log options of container ap to firelens config: missing output key @type which is required for firelens configuration of type fluentd |
ログ出力の設定をfluent-bit形式からfluentd形式に変える必要があります。
FireLensをログドライバとして指定するアプリケーションのログの設定を以下のように変更します。
1 | "logConfiguration": { |
fluent-bitの場合は"Name": "firehose"、"delivery_stream": "kinesis-data-stream"でしたが、fluentdの場合は上記のように設定する必要があります。この辺りのfluent-bitとfluentdの違いについてはタスク定義ファイルで吸収してくれるとありがたいのですが、そうではないようです。
この辺りの設定は以下のページを参考にしました。
https://docs.aws.amazon.com/ja_jp/AmazonECS/latest/userguide/using_firelens.html
最後にgithub actionsでデプロイして無事ログが結合された状態でKinesis Data Firehoseに渡ることが確認できました。S3上でも分割されていないことが確認できました。
まとめ
fluent-bitにはconcatプラグインがなかったのと、AWS推奨のfluentdイメージがなかったので、fluentd公式のイメージをベースにイメージをビルドしました。
タスク定義ファイルでもfluent-bitとfluentdの違いに少し戸惑ったのと、ECSならではの自動化された設定をこちらで準備してはいけないということころで、少しハマりました。
次回はflunet.confにあるTIMEOUTラベルについて記載したいと思います。